Study Guide
CFA L2 2024 Volume 1 - Quantitative Methods
-
University:
CFA Institute -
Course:
CFA Level 2 - Quantitative Methods Academic year:
2024
-
Views:
422
Pages:
168
Author:
customer-8542980
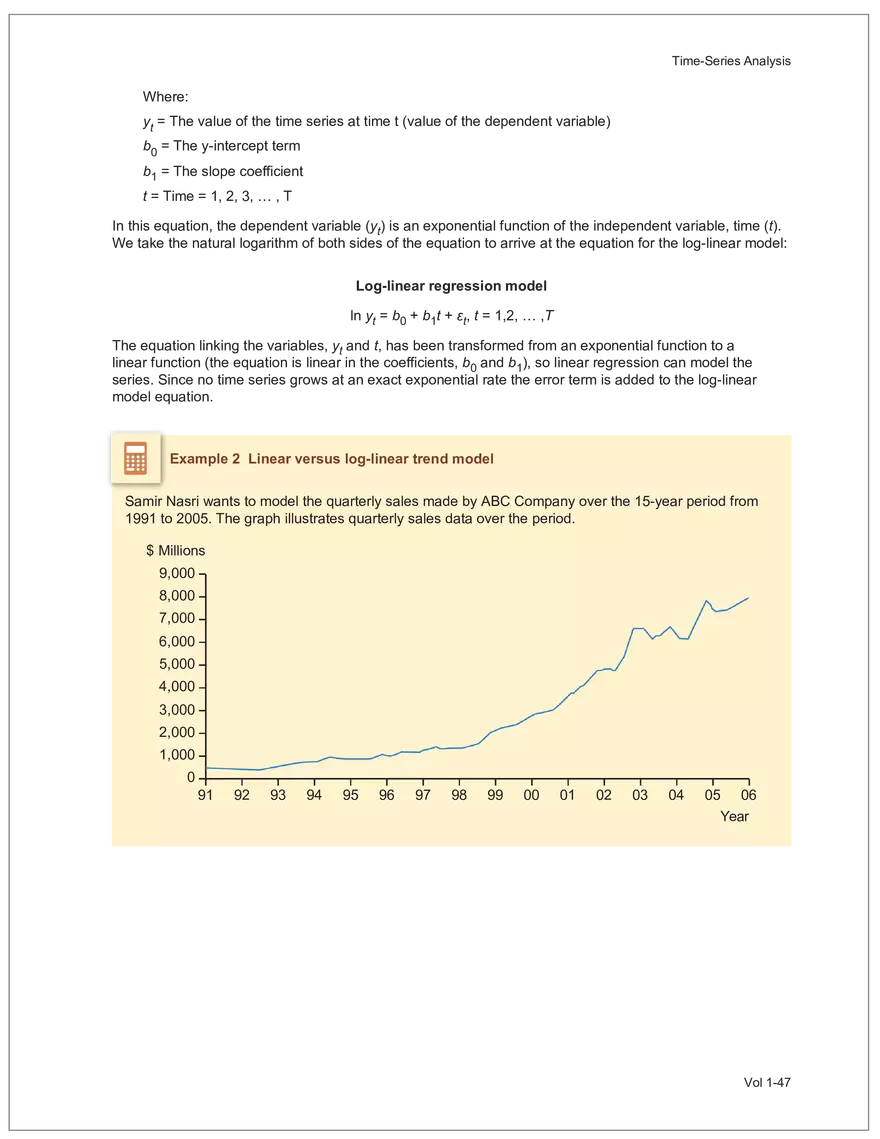
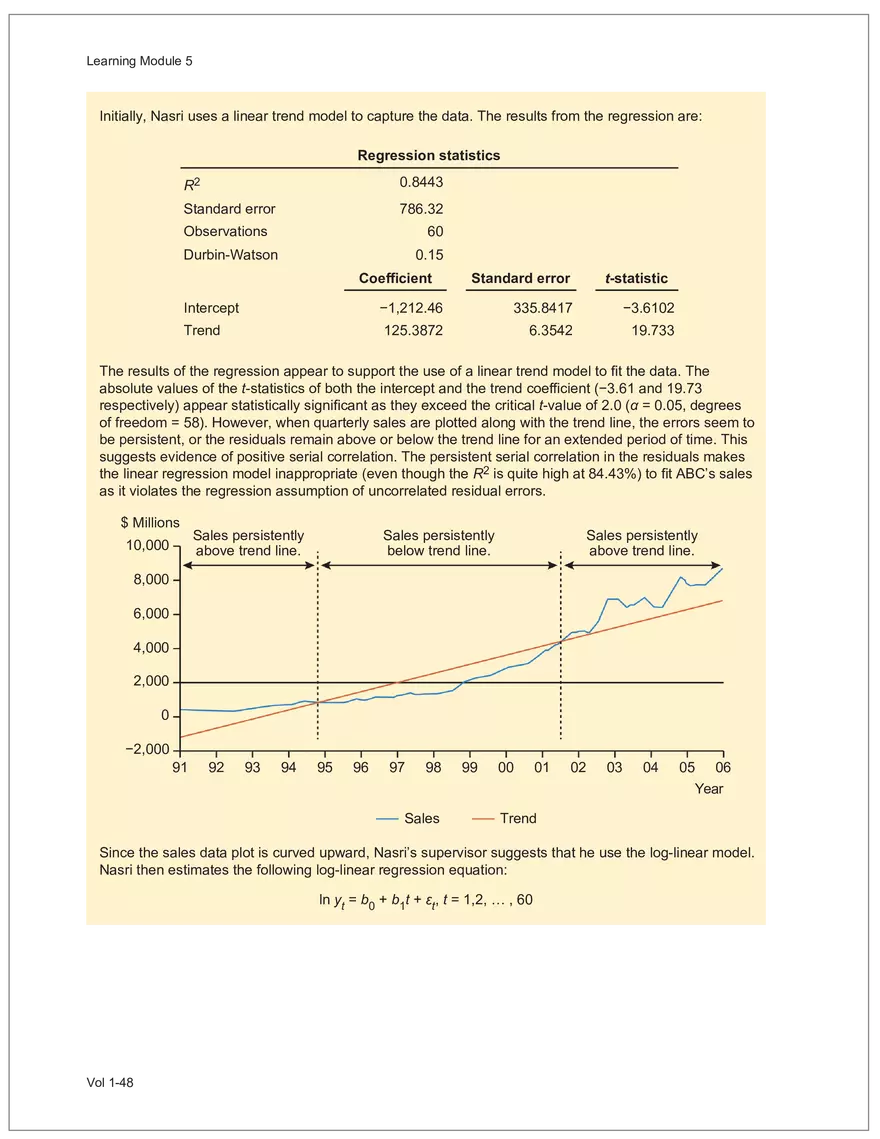
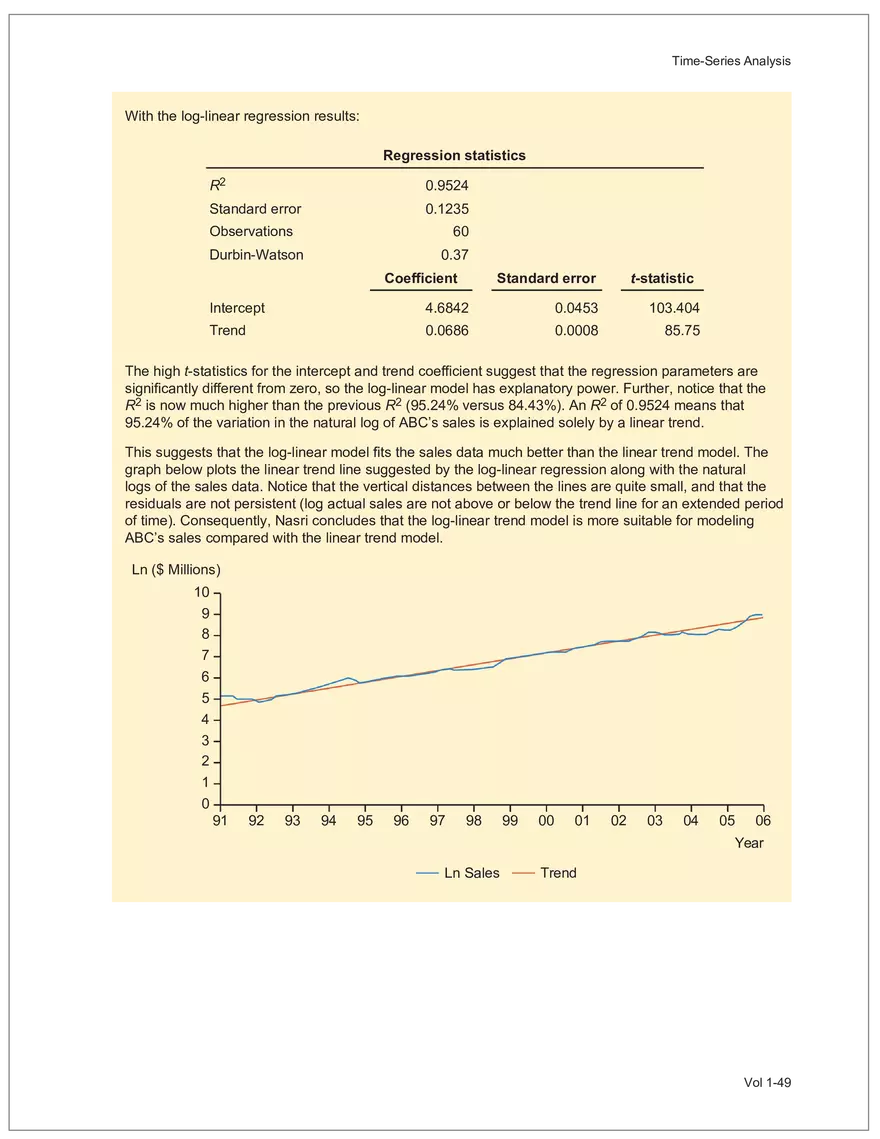
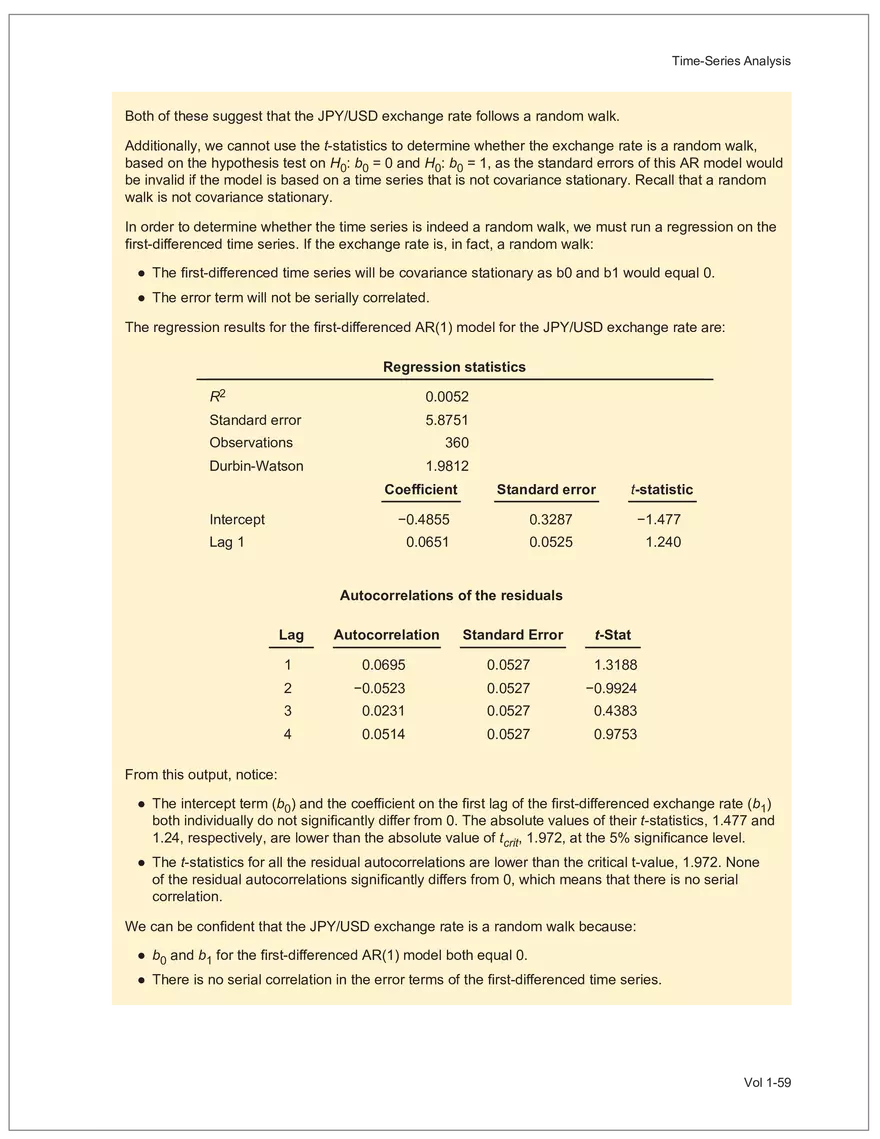
Net sales were $8,514 million, an increase of 5.3%.
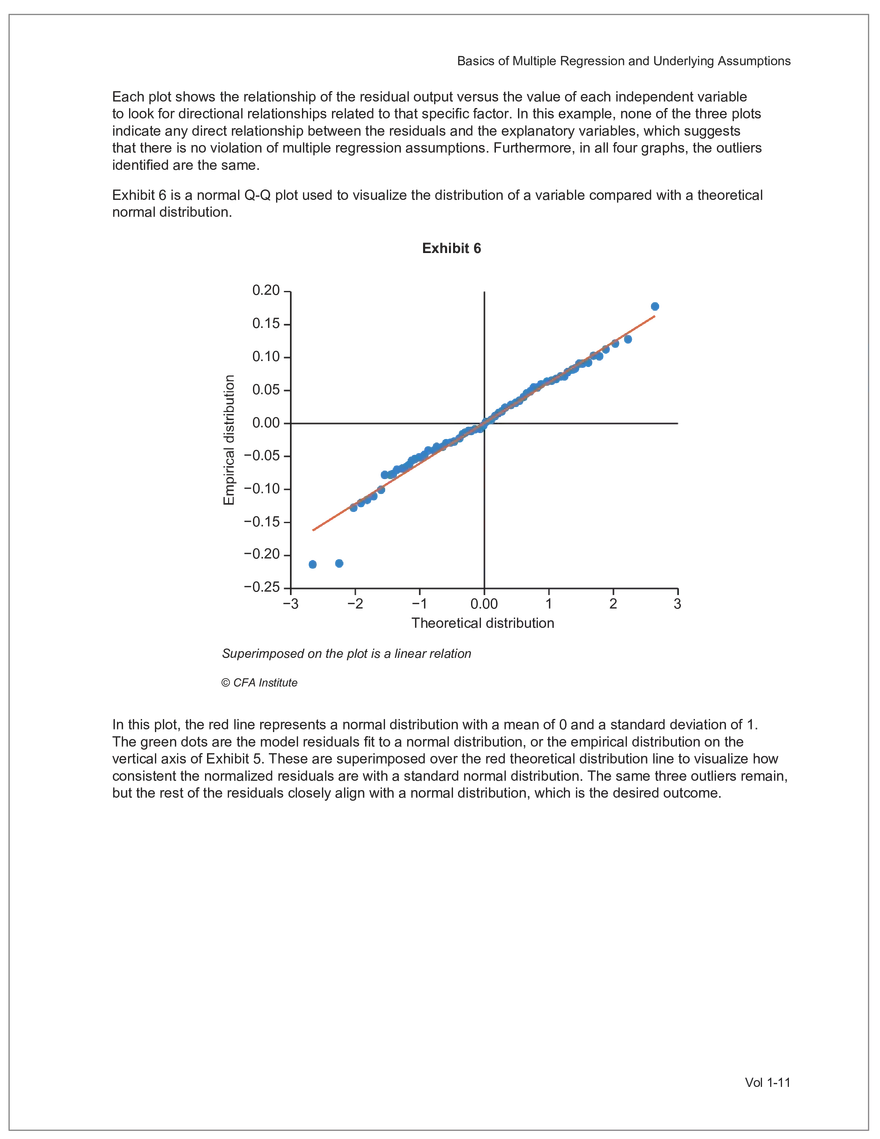
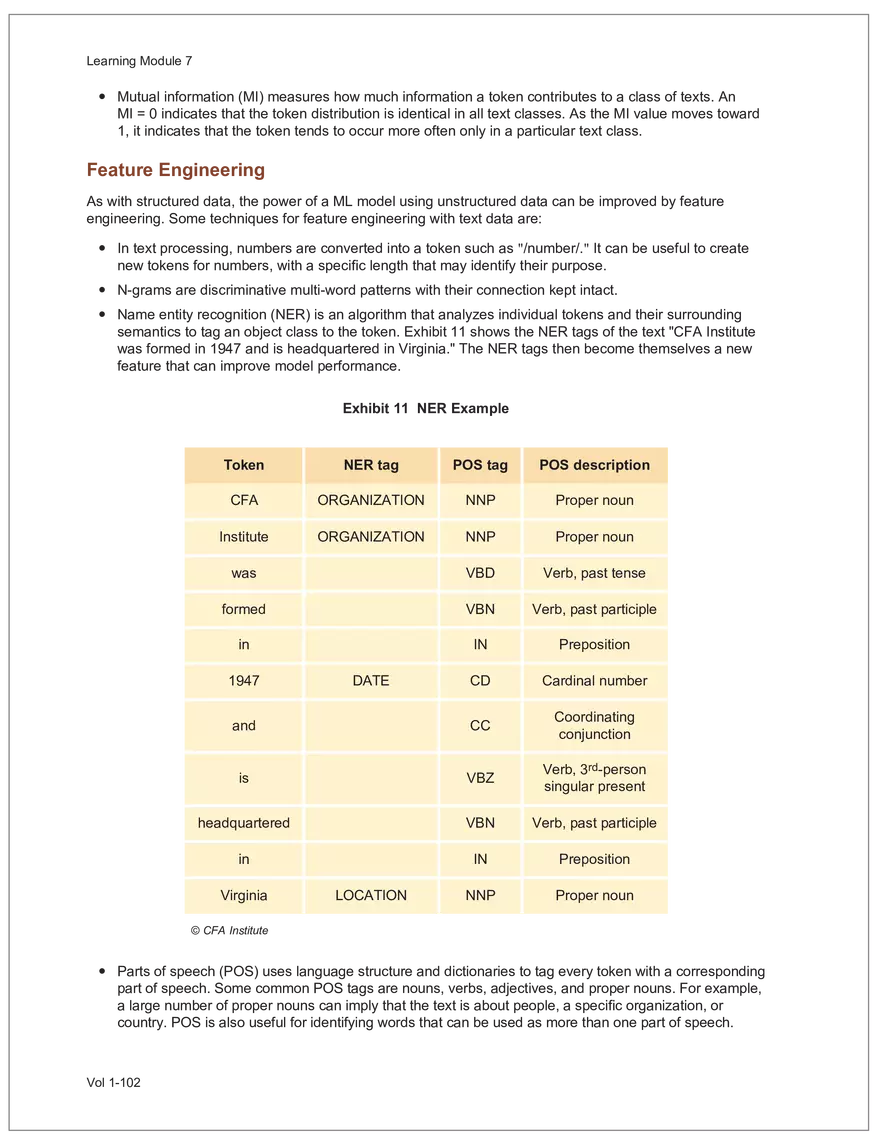
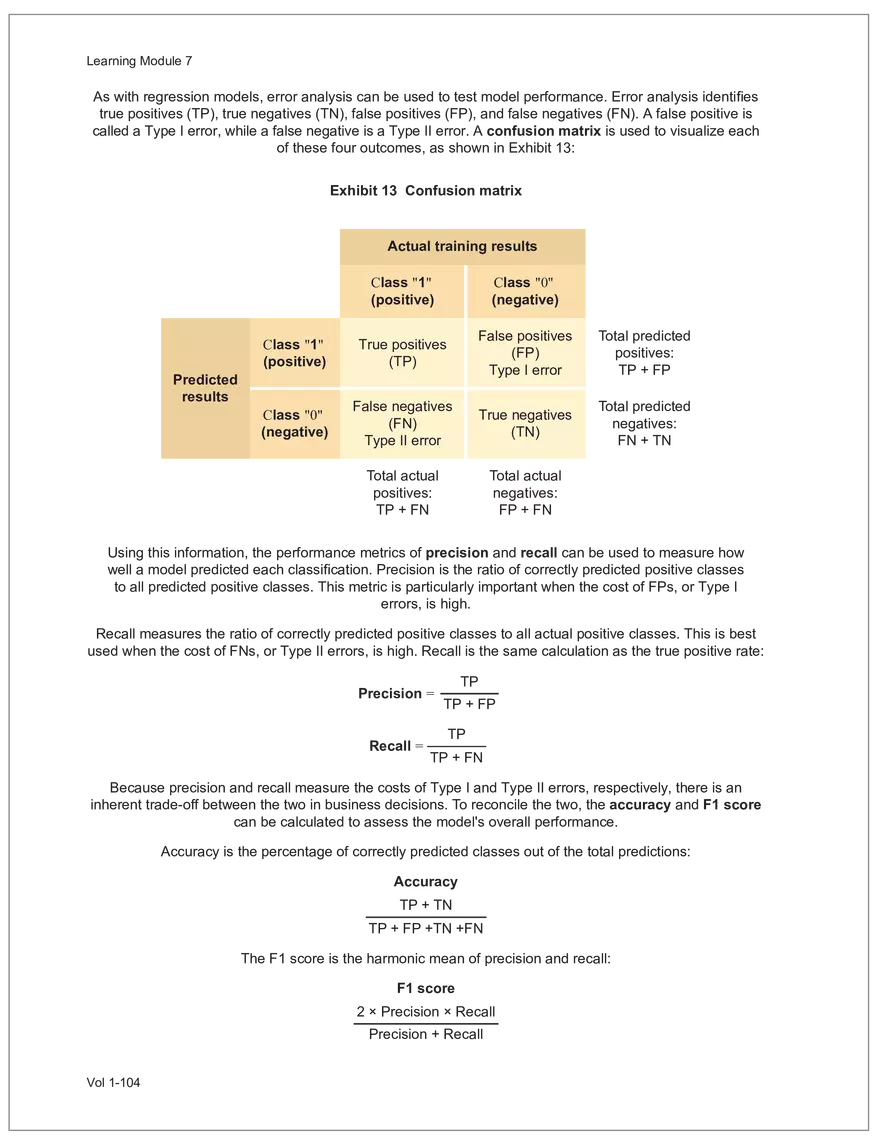
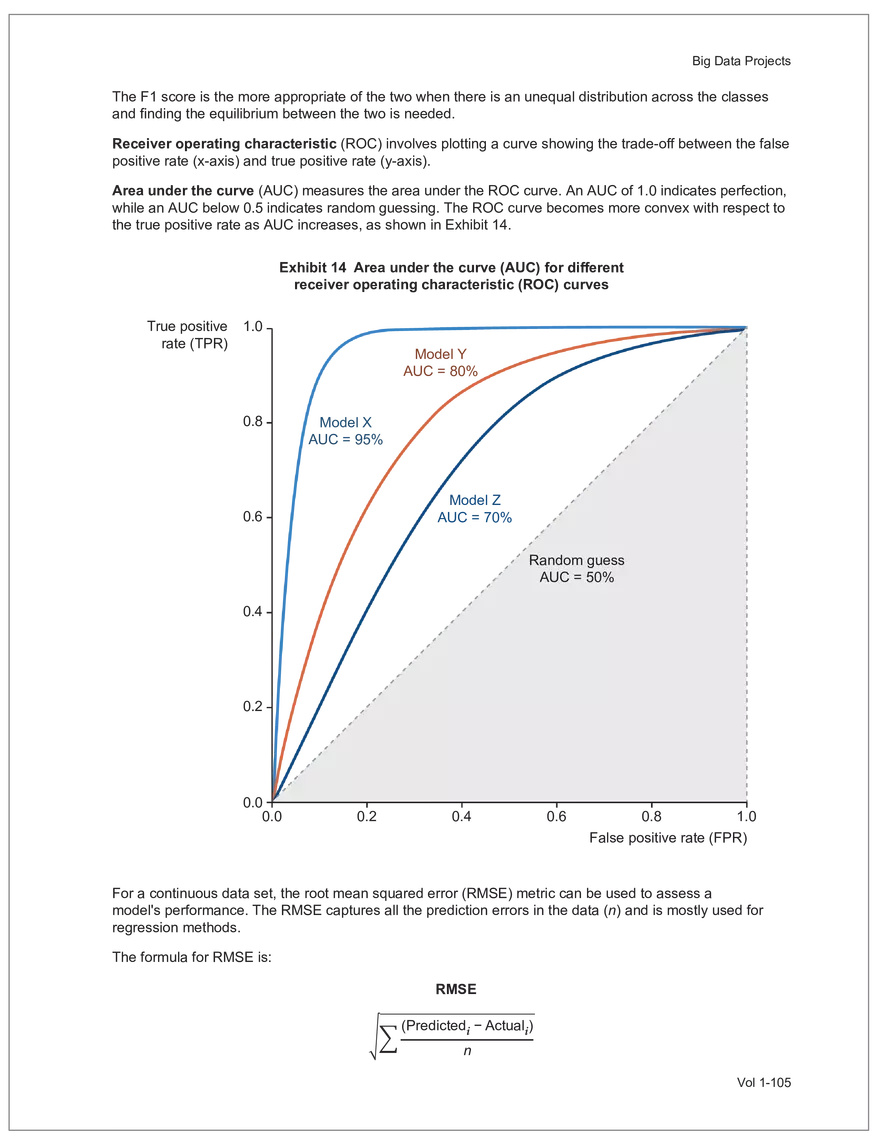
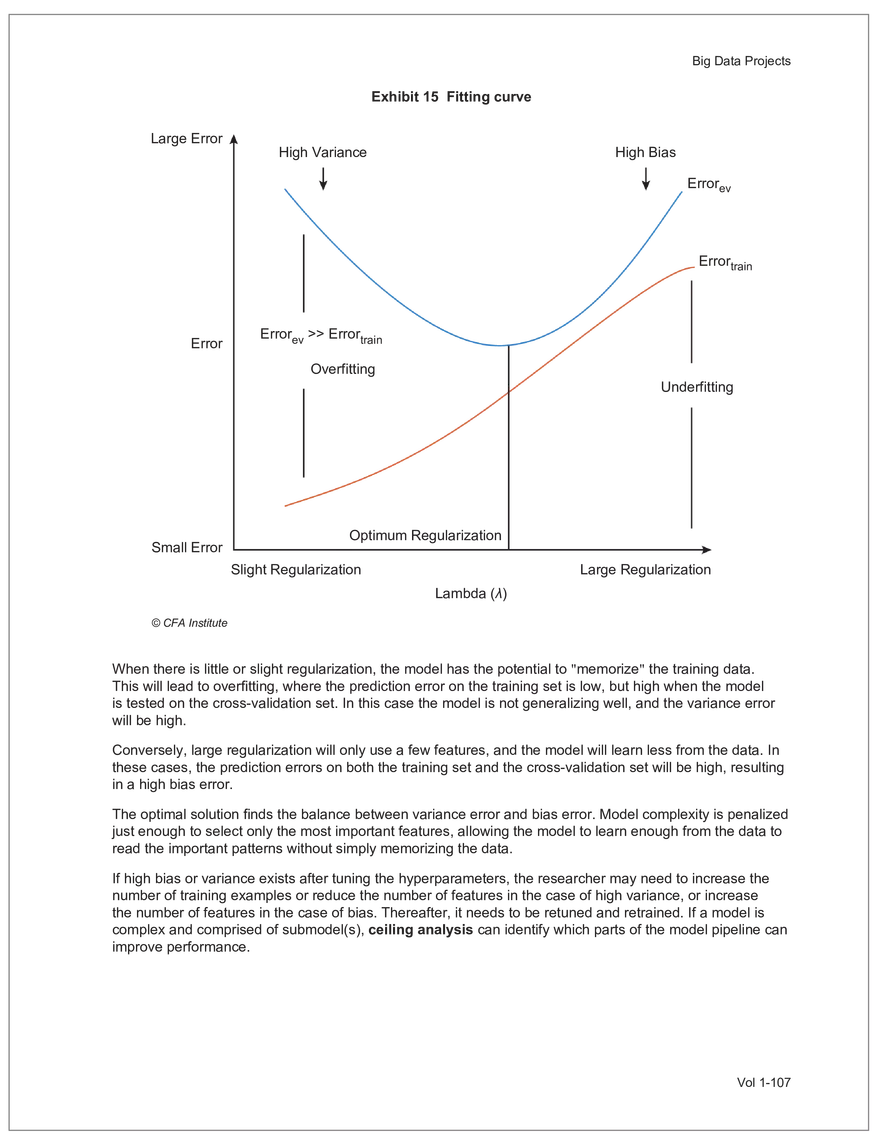
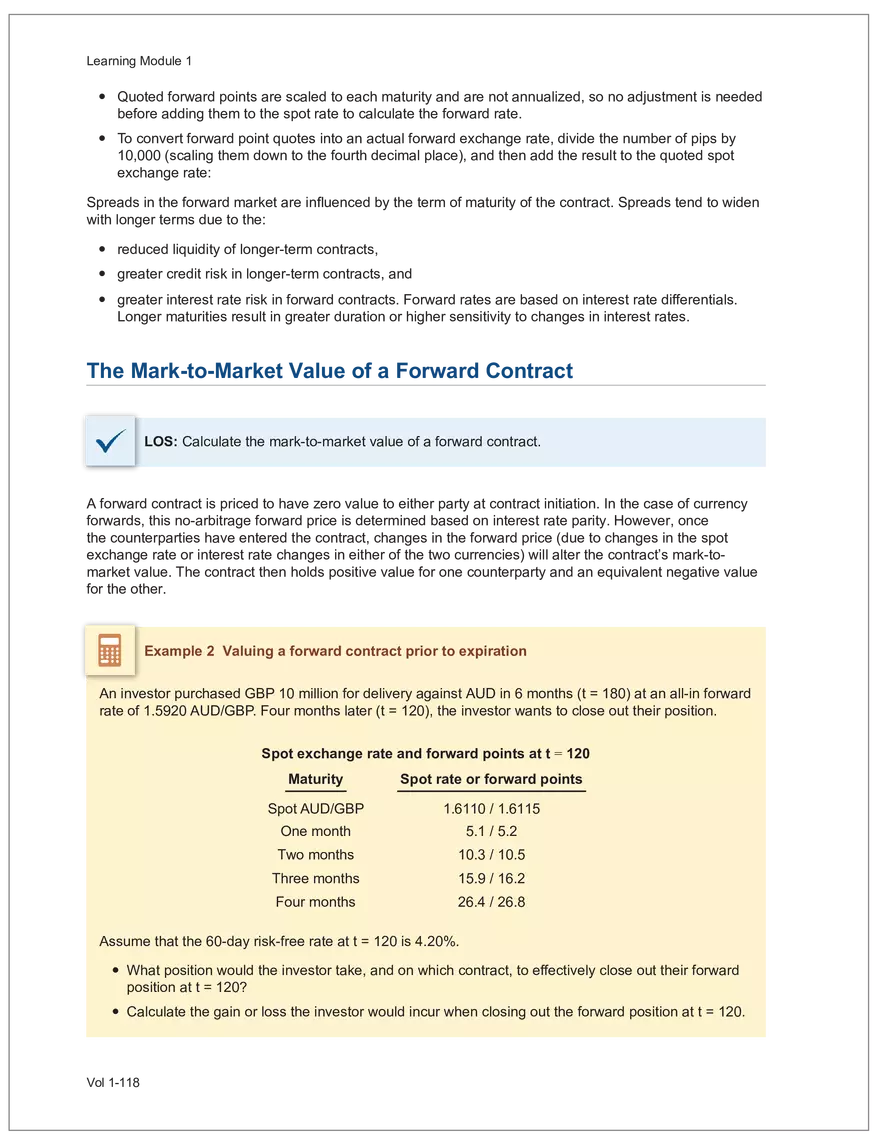
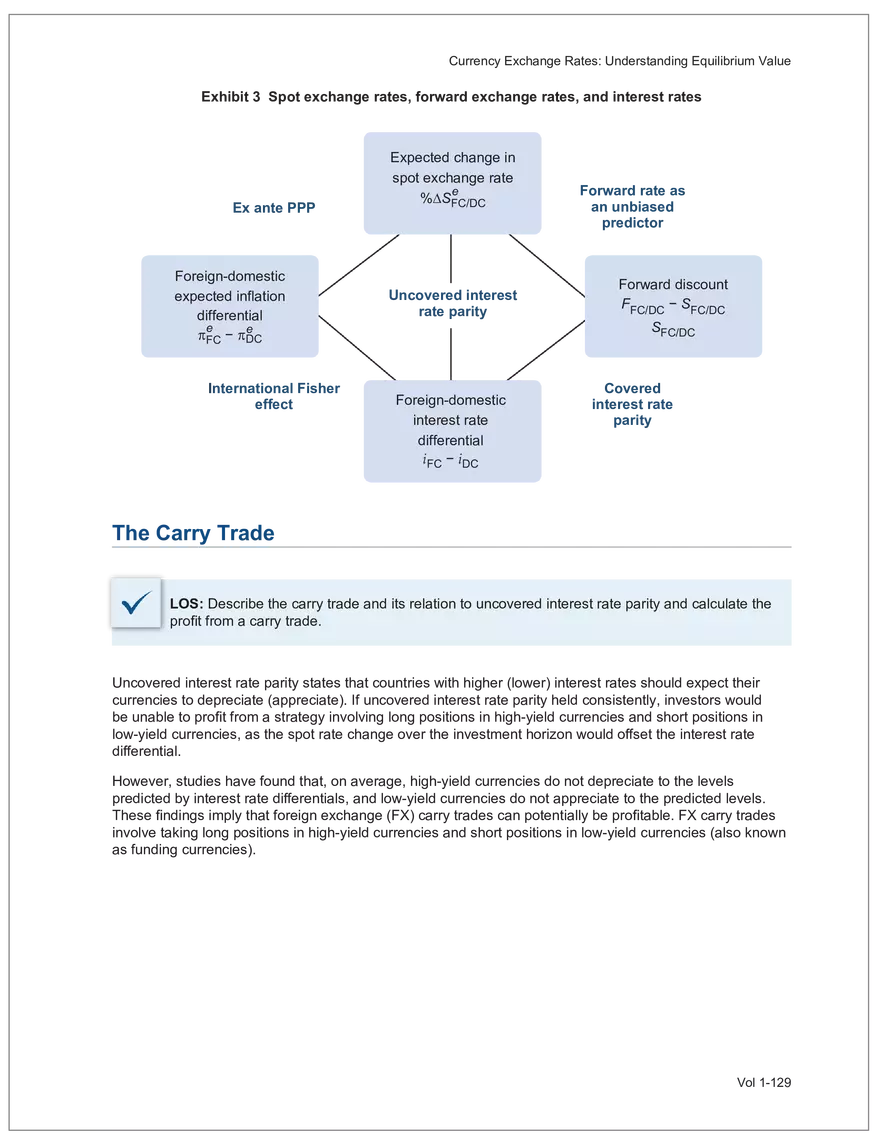
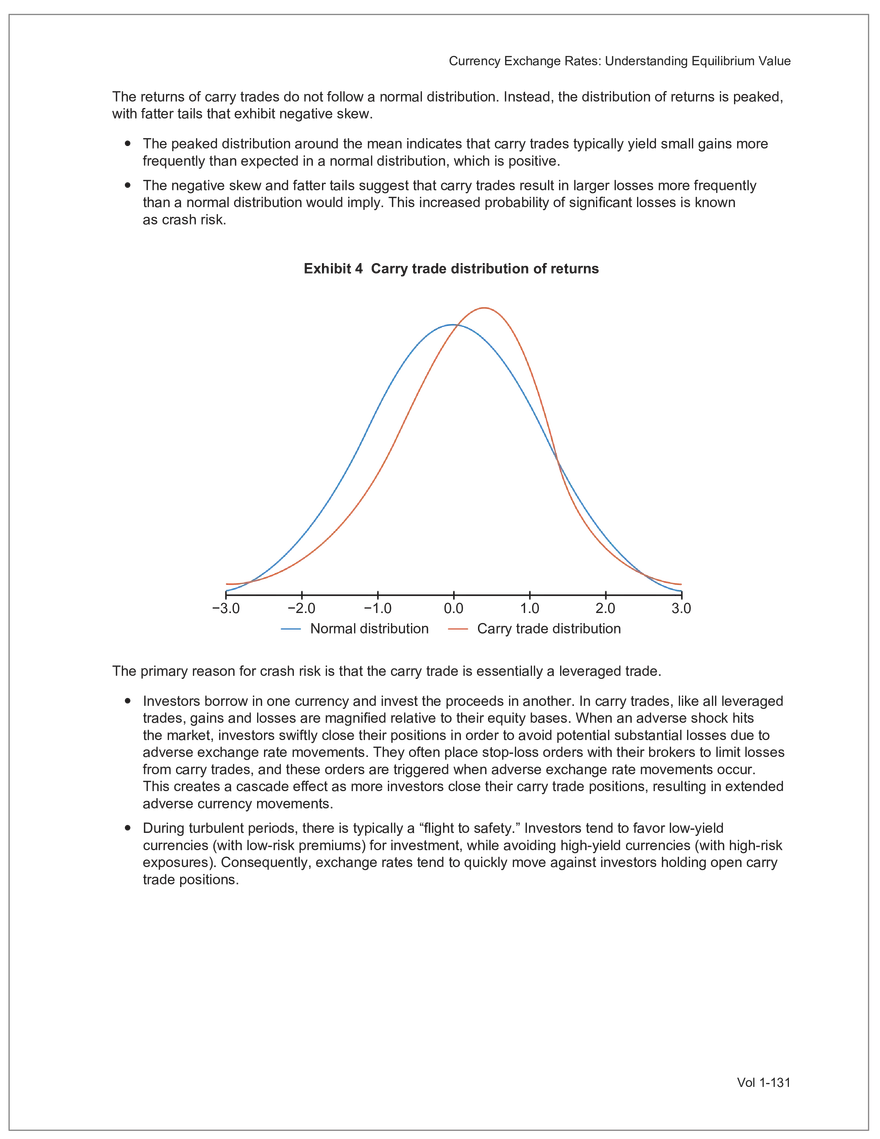
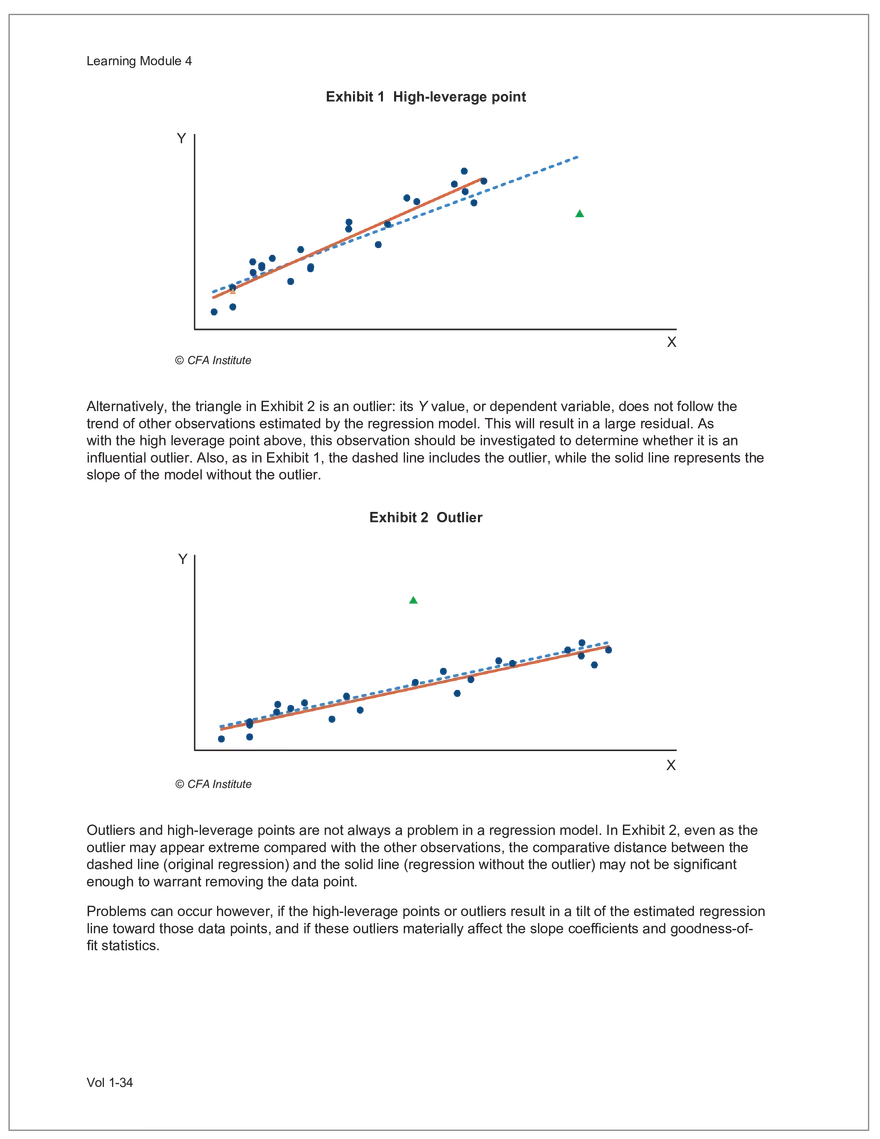
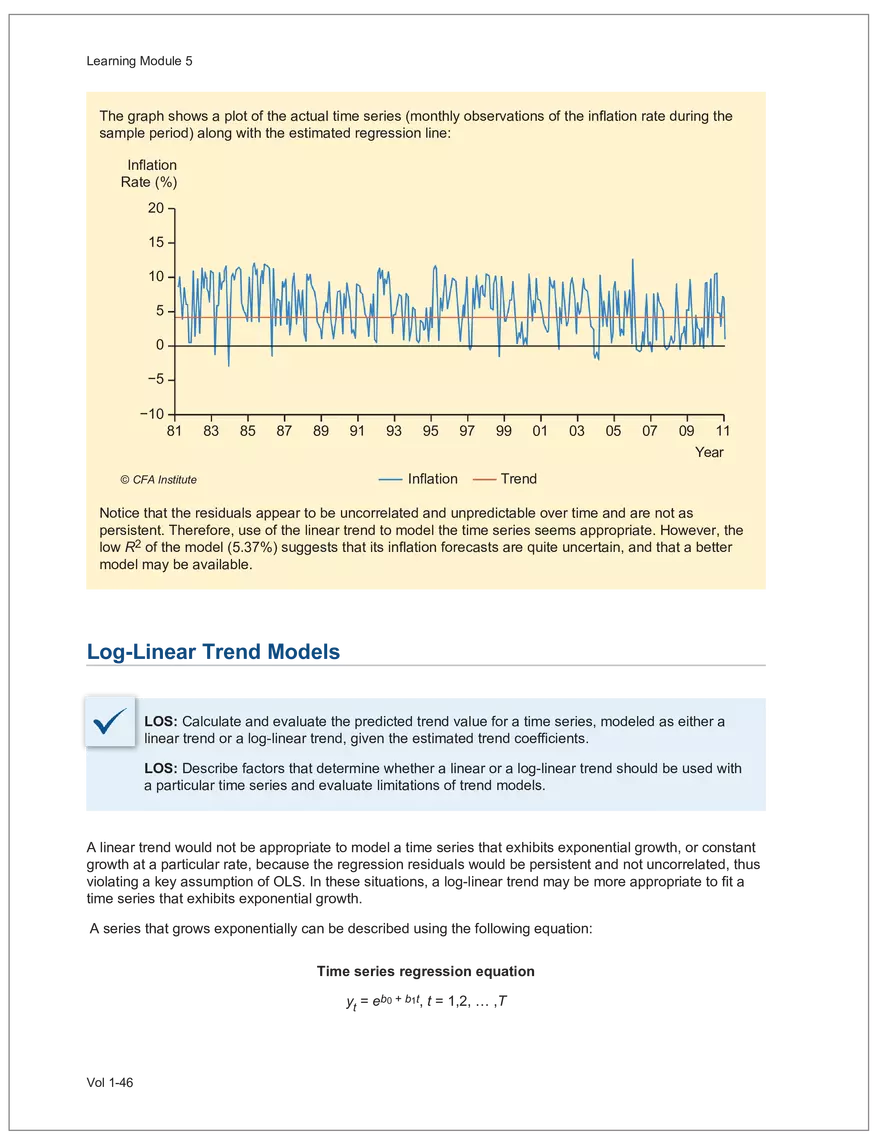
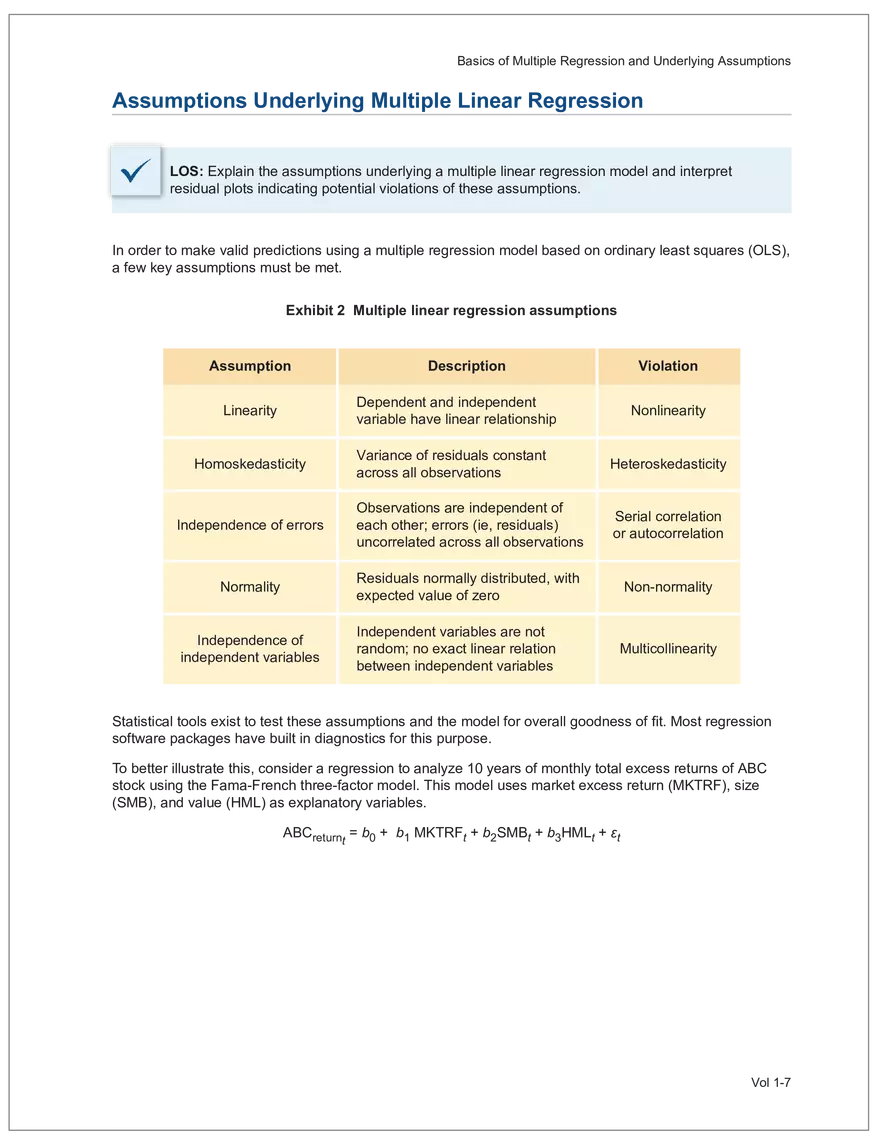
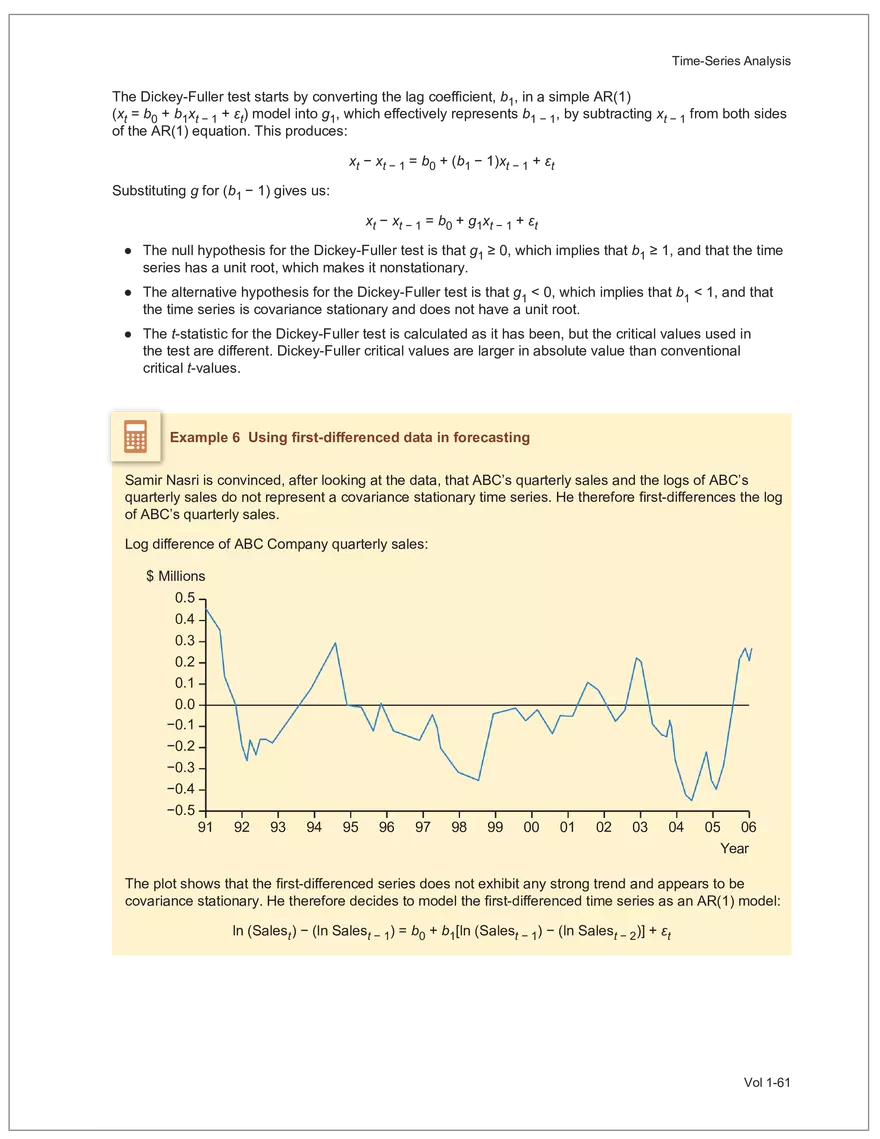
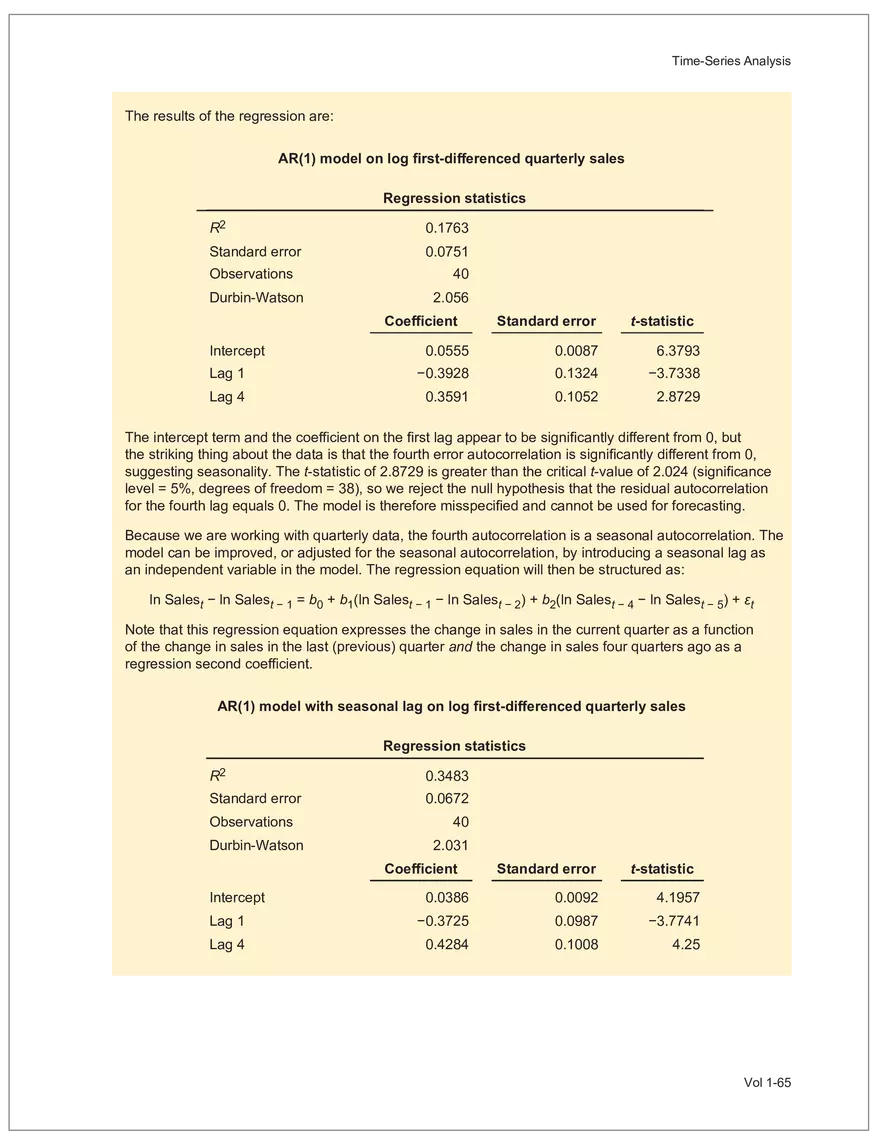
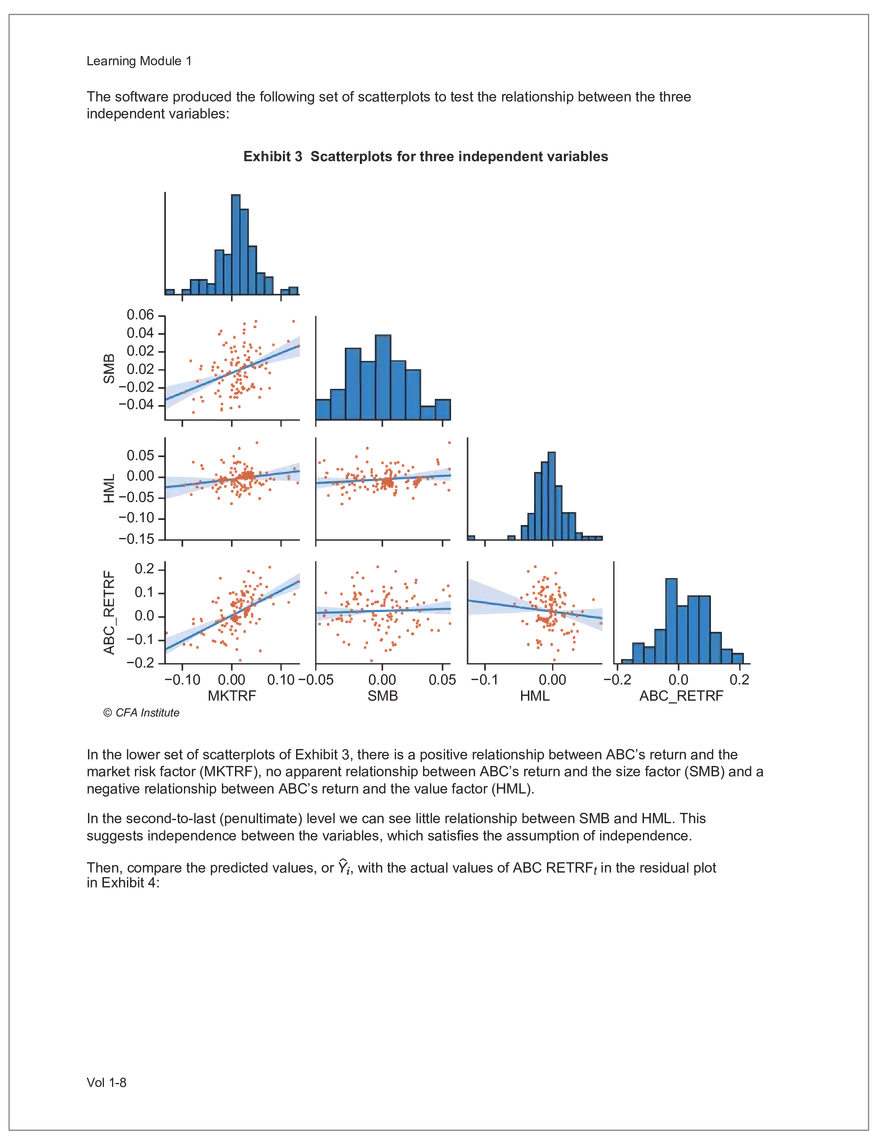
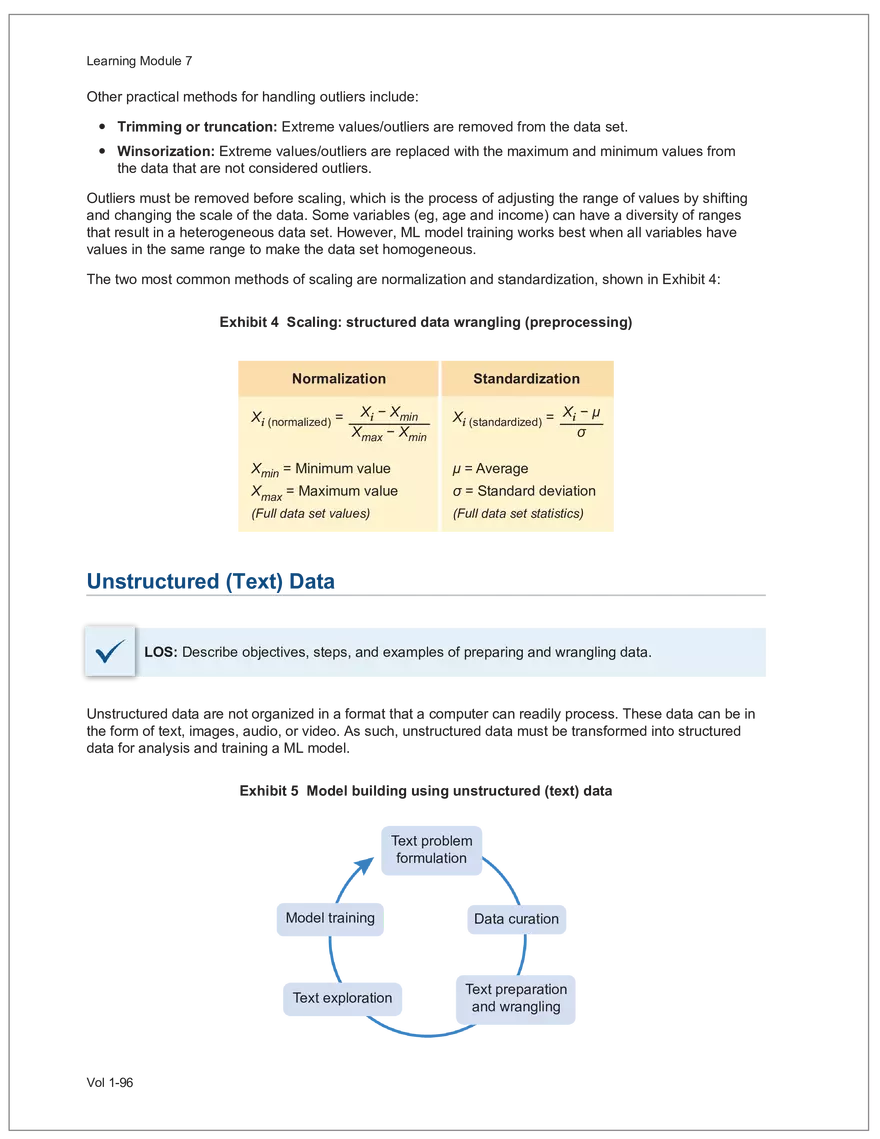
Find and remove HTML tags Net sales were $8,514 million, an increase of 5.3%. Find and remove or substitute punctuation Net sales were /dollarSign/ 8514 million an increase of 53 /percentSign/ /end Sentence/ Find and replace numbers Net sales were /dollarSign/ /number/ million an increase of /number/ /percentSign/ /endSentence/ Find and remove extra white spaces Net sales were/dollarSign//number/million an increase of /number//percentSign//endSentence/ Text Wrangling (Preprocessing) Tokenization is the preprocessing step of breaking down the cleaned text into its elemental words or characters. A token is equivalent to a word; tokenization splits a given text into separate tokens. In other words, text is a collection of tokens. Just like structured data, text data requires normalization. Exhibit 7 shows an example of the steps in normalization. Vol 1-97 Learning Module 7 Exhibit 7 Normalization steps Token Group 1 "Bond" "offerings" "in" "June" "totaled" "currencysign" "billion" "and" "were" "not" "significant" Lower case "bond" "offerings" "in" "june" "totaled" "currencysign" "billion" "and" "were" "not" "significant" Remove stop words "bond" "offerings" "june" "totaled" "currencysign" "billion" "significant" Stem Token Group 2 "bond" "offer" "june" "total" "currencysign" "billion" "signific" Lemmatization or stemming may be used to convert inflected words into their morphological roots (or lemmas). Because lemmatization is more computationally expensive and complicated, stemming is a more common approach. Stemming and lemmatization work to reduce the number of repeated words that occur in the text as different variants of the same word, while keeping the context of the original text. Data sets with few repeated words create sparseness in text data and can make training a ML model more complex. Once the clean text data is normalized, a distinct set of tokens is created in a bag-of-words (BOW): a set of words that does not capture the position or sequence of the words in the original text. For modeling purposes, however, it is memory-efficient and manageable for text analysis. The BOW is next used to build a document term matrix (DTM), a structured data table that is widely used for text data. Each row of the matrix represents a single text file, and each column represents a token, as shown in Exhibit 8: Exhibit 8 Example of a document term matrix bond offer june total billion signific Text 1 Text 2 Text 3 Text 4 Text 5 3 2 2 1 0 6 1 0 2 1 0 0 9 5 1 7 4 12 11 7 1 2 1 0 0 9 1 1 11 5 Vol 1-98 Big Data Projects Since BOW does not represent the word sequences or positions, it has limited use for advanced ML training. N-grams are used to solve this problem. N-grams are word sequences that vary in length, for example, a one-word sequence is a unigram, a two-word sequence is a bigram, and so on. Exhibit 9 presents an example of N-grams. Exhibit 9 N-grams: examples Clean text Unigrams Bond offerings in June were not significant "Bond" "offerings" "in" "June" "were" "not" "significant" "Bond_offerings" "offerings_in" "in_June" "June_were" "were_not" "not_significant" Bigrams Trigrams "Bond_offerings_in" "offerings_in_June" "in_June_were" "June_were_not" "were_not_significant" Data Exploration Objectives and Methods LOS: Describe objectives, methods, and examples of data exploration. In the data exploration stage, the prepared data is analyzed to understand distributions and relationships among the features and how they relate to the target outcome. Data exploration involves three key steps: exploratory data analysis, feature selection, and feature engineering. In exploratory data analysis (EDA), exploratory graphs, charts, and other visualizations (eg, heat maps and word clouds) are used to summarize data for inspection. Most statistical software and programs have generic tools that can quickly show these relationships, but data can also be summarized using descriptive statistics and more sophisticated measures for project-specific EDA. Key objectives for EDA include: y Understanding data properties y Finding data patterns and relationships y Establishing basic questions and hypotheses y Documenting data distribution characteristics y Planning modeling strategies Insights taken from the EDA process are then used in feature selection and feature engineering. EDA with Structured Data With structured data, EDA can done on multiple features (multi-dimensional) or on a single feature (onedimensional). For multi-dimensional data, more advanced techniques, like principal component analysis (PCA), can be used. Vol 1-99 Learning Module 7 For one-dimensional data, common summary statistics are used, such as mean, median, standard deviation, quartile ranges, skewness, and kurtosis. Data visualizations can also be created, such as histograms, density plots, bar charts, and box plots. Histograms use equal bins of values or value ranges to show the frequency of the data points in each bin, and thus show the distribution of the data. One-dimensional visualizations of multiple features are often stacked or overlaid on each other in a single plot for comparison. For example, density plots are smoothed histograms overlaid on standard histograms, used to understand the distribution of continuous data by normally distributing the mean, median, and standard deviation. To compare multiple features, multivariate data visualizations include stacked bar charts, multiple box plots, and scatterplots. Scatterplots are helpful to show the relationship between two variables. Feature Selection In the feature selection stage, the researcher selects the most pertinent variables for ML model training in order to simplify the model. Throughout the EDA stage, features that are both relevant and irrelevant are identified, but statistical diagnostics are used to remove redundancy, heteroskedasticity, and multicollinearity, with the goal of minimizing the number of features while also maximizing the predictive power of the model. Dimensionality reduction identifies features that account for the greatest variance between observations, reduces the volume of data, and creates new, uncorrelated combinations of features. But while both feature selection and dimensionality reduction reduce the number of features, neither involves altering the data. Feature Engineering Feature engineering produces new features derived from the given features to help better explain the data set. A ML model can only perform as well as the data used to train it, and feature engineering can improve the data by uncovering structures inherent, but not explicit, in the data. Techniques include altering, combining, or decomposing existing data. For example, for continuous data, a new feature may be just the logarithm of another, which is helpful if the data spans a large range or if the percentage differences are important. Other examples include bracketing by assigning a binary to a data point. converting categorical variables into a binary value; this is known as one hot encoding and is common in handling categorical data in ML. Unstructured Data: Text Exploration LOS: Describe objectives, methods, and examples of data exploration. LOS: Describe methods for extracting, selecting, and engineering features from textual data. Exploratory Data Analysis Text statistics vary by case and are used to analyze and reveal word patterns. Computing basic test statistics using tokens is known as term frequency (TF), which is the ratio of how often a particular token occurs to the total number of tokens in the data set. A collection of text data sets is called a corpus. Vol 1-100 For categorical data, new features can combine two features or decompose one feature into many, Big Data Projects Topic modeling is a text data application where the most informative words are identified by calculating methods such as a word cloud, which visualizes the most informative words and their TF values. Exhibit 10 is an example of a word cloud where the size of each word is decided by its TF value. Exhibit 10 Word cloud interpretation from Alphabet's 20XX 10-K filing Total revenue Result of operations Cost of revenue Google cloud Increase Fair value Effective tax rate Product mix Income tax Google search Marketable security Google service Foreign exchange effect Google playImpact of covid-19 Device mix Data center Paid click Data Currency exchange rate Distribution partner Net cash revenue US dollars Geographic mix Foreign currency Marketable equity security Financial result Content acquisition cost Marketing expenses Compensation expenses Purchase of property Feature Selection This stage removes a subset of tokens in the data with high TF values that are not material to the project. These stop words are taken out of the corpus to decrease vocabulary size, or the BOW, which makes the ML model simpler and thus more efficient, eliminating noisy features from the data set or tokens that detract from or fail to benefit ML model training. y Frequent tokens strain a ML model in deciding boundaries among texts, which causes model underfitting. y Rare tokens mislead a ML model into classifying texts that contain rare terms into a specific class, leading to model overfitting. To minimize the impacts of these data points, the researcher can use general feature selection methods for identifying and removing noisy features: y Frequency measures reduce vocabulary by filtering tokens with very high and low TF values. y Document frequency (DF) discards noisy features that carry no material information across all texts. The DF of a token is calculated as the number of documents that contain that token divided by the number of total documents in the data set. y Chi-square tests examine the independence of two events: occurrence of the token and occurrence of the class. The test ranks each token by its usefulness to each class in a text classification problem. Tokens with higher chi-square test statistics for a given class are more frequently associated and therefore have a higher discriminatory potential. Vol 1-101 TF. Using the TF, text statistics can be visually comprehended in the same way as structured data, using revenue percentage changes Information technology assets Advertising revenue Google network member Financial conditions revenue growth rate Cost Fair value Interest rate Learning Module 7 y Mutual information (MI) measures how much information a token contributes to a class of texts. An MI = 0 indicates that the token distribution is identical in all text classes. As the MI value moves toward 1, it indicates that the token tends to occur more often only in a particular text class. Feature Engineering As with structured data, the power of a ML model using unstructured data can be improved by feature engineering. Some techniques for feature engineering with text data are: y In text processing, numbers are converted into a token such as "/number/." It can be useful to create new tokens for numbers, with a specific length that may identify their purpose. y N-grams are discriminative multi-word patterns with their connection kept intact. y Name entity recognition (NER) is an algorithm that analyzes individual tokens and their surrounding semantics to tag an object class to the token. Exhibit 11 shows the NER tags of the text "CFA Institute was formed in 1947 and is headquartered in Virginia." The NER tags then become themselves a new feature that can improve model performance. Exhibit 11 NER Example Token CFA NER tag POS tag NNP NNP VBD VBN IN POS description ORGANIZATION Proper noun Institute ORGANIZATION was Proper noun Verb, past tense Verb, past participle Preposition formed in 1947 DATE CD Cardinal number Coordinating conjunction and is CC Ve rd rb, 3 -person VBZ singular present Verb, past participle Preposition headquartered in VBN IN Virginia LOCATION NNP Proper noun © CFA Institute y Parts of speech (POS) uses language structure and dictionaries to tag every token with a corresponding part of speech. Some common POS tags are nouns, verbs, adjectives, and proper nouns. For example, a large number of proper nouns can imply that the text is about people, a specific organization, or country. POS is also useful for identifying words that can be used as more than one part of speech. Vol 1-102 Big Data Projects Model Training, Structured versus Unstructured Data, and Method Selection LOS: Describe objectives, steps, and techniques in model training. Once the features are selected, the ML model can be trained. The training process is systematic, iterative, and recursive and can become fairly complex. The nature of the problem at hand, the input data available, and the level of performance needed to apply the model dictate that complexity. However, all ML model training involves three tasks: method selection, performance evaluation, and tuning. Method Selection There are no set guidelines on which method to fit a model with. However, there are a few factors that steer the researcher toward a broader process: y Supervised or unsupervised learning: Supervised models have a ground truth, or a target dependent variable that adds structure to the model. They can aim to predict a continuous value (regression) or a set classification of a dependent variable. Unsupervised learning aims to reduce the number of features that define the data set and group data points by similarities not immediately evident in the data. y Type of data, such as numerical, text, images, or speech y Size of data, including both the number of instances and features Further complicating the model selection process are data sets with mixed inputs (eg, both numerical and text data or both structured and unstructured data). In these cases, the results of one model can be used as an input for another model. Performance Evaluation Measuring a model's performance is a critical step in assessing its goodness of fit. For models that predict continuous variables, analysis of the error terms is used to measure fit. However, for binary classification models, there are several techniques available to assess performance. Exhibit 12 shows three of these techniques. Exhibit 12 Techniques of ML performance evaluation y Actual vs. predicted results (confusion matrix) Error analysis y Metrics: precision, recall, accuracy, and F1 score y Trade-off between false and true positive rates y Distinct cutoff points and areas under the curve (AUC) y Greater AUC (closer to 1) means better performance Receiver operating characteristic (ROC) y Appropriate for continuous data and regressions y Measures all prediction errors Root mean square error (RMSE) y Smaller RMSE means better performance Vol 1-103 y True/false positives/negatives: TP, FP, FN, TN Learning Module 7 As with regression models, error analysis can be used to test model performance. Error analysis identifies true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN). A false positive is called a Type I error, while a false negative is a Type II error. A confusion matrix is used to visualize each of these four outcomes, as shown in Exhibit 13: Exhibit 13 Confusion matrix Actual training results Class "1" Class "0" (positive) (negative) False positives (FP) Type I error Total predicted positives: Class "1" (positive) True positives (TP) TP + FP Predicted results False negatives (FN) Type II error Total predicted negatives: FN + TN Class "0" (negative) True negatives (TN) Total actual positives: TP + FN Total actual negatives: FP + FN Using this information, the performance metrics of precision and recall can be used to measure how well a model predicted each classification. Precision is the ratio of correctly predicted positive classes to all predicted positive classes. This metric is particularly important when the cost of FPs, or Type I errors, is high. Recall measures the ratio of correctly predicted positive classes to all actual positive classes. This is best used when the cost of FNs, or Type II errors, is high. Recall is the same calculation as the true positive rate: TP Precision = TP + FP TP Recall = TP + FN Because precision and recall measure the costs of Type I and Type II errors, respectively, there is an inherent trade-off between the two in business decisions. To reconcile the two, the accuracy and F1 score can be calculated to assess the model's overall performance. Accuracy is the percentage of correctly predicted classes out of the total predictions: Accuracy TP + TN TP + FP +TN +FN The F1 score is the harmonic mean of precision and recall: F1 score 2 × Precision × Recall Precision + Recall Vol 1-104 Big Data Projects The F1 score is the more appropriate of the two when there is an unequal distribution across the classes and finding the equilibrium between the two is needed. Receiver operating characteristic (ROC) involves plotting a curve showing the trade-off between the false positive rate (x-axis) and true positive rate (y-axis). Area under the curve (AUC) measures the area under the ROC curve. An AUC of 1.0 indicates perfection, while an AUC below 0.5 indicates random guessing. The ROC curve becomes more convex with respect to the true positive rate as AUC increases, as shown in Exhibit 14. Exhibit 14 Area under the curve (AUC) for different receiver operating characteristic (ROC) curves True positive 1.0 rate (TPR) Model Y AUC = 80% 0.8 0.6 0.4 0.2 0.0 Model X AUC = 95% Model Z AUC = 70% Random guess AUC = 50% 0.0 0.2 0.4 0.6 0.8 1.0 False positive rate (FPR) For a continuous data set, the root mean squared error (RMSE) metric can be used to assess a model's performance. The RMSE captures all the prediction errors in the data (n) and is mostly used for regression methods. The formula for RMSE is: RMSE (Predicted − Actual ) i i �� n Vol 1-105 Learning Module 7 Tuning LOS: Describe objectives, steps, and techniques in model training. Once a model's performance has been evaluated, steps can be taken to improve its performance. A high prediction error on the training set indicates that the model is underfitting, while higher prediction errors on the cross-validation set compared with the training set tell the researcher that the model is overfitting. There are two types of errors when model fitting: y Bias error is high when the model underfits the training data. This generally occurs when the model is underspecified and the model is not adequately learning from the patterns in the training data. In these cases, both the training set prediction errors and cross-validation errors will be large. y Variance error is high when the model overfits to the training data, or the model is overly complicated. The training set prediction error will be much lower than on the cross-validation set. Neither of these errors can be completely eliminated, but the trade-off between the two errors should minimize the aggregate error over the data series. Balance is necessary to finding the optimal model that neither underfits nor overfits. Finding the correct model parameters, such as regression coefficients, weights in neural networks (NNs), and support vectors in support vector machines, is critical to properly fitting a model. The model parameters are dependent on the training data and are learned during the training process through optimization techniques. Hyperparameters are not dependent on training data and are used for estimating model parameters. Examples of these include the regularization term (λ) in supervised models, activation function and number of hidden layers in NNs, number of trees and tree depth in ensemble methods, k in k-nearest neighbor classification and k-means clustering, and p-threshold in logistic regression. Researchers optimize hyperparameters based on tuning heuristics and grid searches rather than using an estimation formula. A grid search is a method for training ML models through combinations of hyperparameter values and cross-validation to produce optimal model performance (training error and cross-validation error are close), which leads to a lower probability of overfitting. The plot of training errors for each hyperparameter is called a fitting curve, shown in Exhibit 15: Vol 1-106 Big Data Projects Exhibit 15 Fitting curve Large Error High Variance High Bias Errorev Error train Error >> Error E ev train rror Overfitting Underfitting Optimum Regularization Slight Regularization Small Error Large Regularization Lambda (λ) © CFA Institute When there is little or slight regularization, the model has the potential to "memorize" the training data. This will lead to overfitting, where the prediction error on the training set is low, but high when the model is tested on the cross-validation set. In this case the model is not generalizing well, and the variance error will be high. Conversely, large regularization will only use a few features, and the model will learn less from the data. In these cases, the prediction errors on both the training set and the cross-validation set will be high, resulting in a high bias error. The optimal solution finds the balance between variance error and bias error. Model complexity is penalized just enough to select only the most important features, allowing the model to learn enough from the data to read the important patterns without simply memorizing the data. If high bias or variance exists after tuning the hyperparameters, the researcher may need to increase the number of training examples or reduce the number of features in the case of high variance, or increase the number of features in the case of bias. Thereafter, it needs to be retuned and retrained. If a model is complex and comprised of submodel(s), ceiling analysis can identify which parts of the model pipeline can improve performance. Vol 1-107 Learning Module 7 Vol 1-108 Economics Learning Module 1 Currency Exchange Rates: Understanding Equilibrium Value LOS: Calculate and interpret the bid-offer spread on a spot or forward currency quotation and describe the factors that affect the bid-offer spread. LOS: Identify a triangular arbitrage opportunity and calculate its profit, given the bid-offer quotations for three currencies. LOS: Explain spot and forward rates and calculate the forward premium/discount for a LOS: Calculate the mark-to-market value of a forward contract. LOS: Explain international parity conditions (covered and uncovered interest rate parity, forward rate parity, purchasing power parity, and the international Fisher effect). LOS: Describe relations among the international parity conditions. LOS: Evaluate the use of the current spot rate, the forward rate, purchasing power parity, and uncovered interest parity to forecast future spot exchange rates. LOS: Explain approaches to assessing the long-run fair value of an exchange rate. LOS: Describe the carry trade and its relation to uncovered interest rate parity and calculate the profit from a carry trade. LOS: Explain how flows in the balance of payment accounts affect currency exchange rates. LOS: Explain the potential effects of monetary and fiscal policy on exchange rates. LOS: Describe objectives of central bank or government intervention and capital controls and describe the effectiveness of intervention and capital controls. LOS: Describe warning signs of a currency crisis. Foreign Exchange Market Concepts LOS: Calculate and interpret the bid-offer spread on a spot or forward currency quotation and describe the factors that affect the bid-offer spread. An exchange rate represents the price of one currency in terms of another currency. It is stated as the number of units of a particular currency (the price currency) required to purchase one unit of another currency (the base currency). Vol 1-111 given currency. Learning Module 1 CFA curriculum uses the convention P/B: the number of units of the price (P) currency needed to purchase one unit of the base (B) currency. For example, suppose the USD/GBP exchange rate is currently 1.5125. From this exchange rate quote, we can infer the following: y 1 GBP will buy 1.5125 USD. y A decrease in the exchange rate (eg, from 1.5125 to 1.5120) means that 1 GBP will be able to purchase fewer USD. ○ Fewer USD will now be required to purchase 1 GBP (ie, the cost of 1 GBP has fallen). ○ This decrease in the exchange rate means that the GBP has depreciated (ie, lost value) against the Just like the price of any product, the price reflected in an exchange rate is the amount of the numerator Spot exchange rates (S) are quotes for transactions that call for immediate delivery. For most currencies, immediate delivery means “T + 2” (ie, the transaction is settled 2 days after the trade is agreed upon by the parties). In professional FX markets, an exchange rate is usually quoted as a two-sided price. Dealers typically quote both a bid price (ie, the price at which they are willing to buy) and an offer price (ie, the price at which they Bid-offer quotes in foreign exchange have two main points: y The offer price is higher than the bid price, which creates the bid-offer spread, a compensation for providing foreign exchange. y Requesting a two-sided quote from the dealer allows a choice between whether the base currency will be bought (ie, paying the offer) or sold (ie, hitting the bid). This choice provides flexibility in transactions. In FX, dealers have two pricing levels: one level for clients and another for the interbank market. Dealers engage in currency transactions among themselves in the interbank market in order to adjust their inventories and risk positions, distribute foreign currencies to clients, and transfer FX rate risk to willing market participants. This global network handles large transactions, typically over 1 million units of the base currency; nonbank entities like institutional asset managers and hedge funds can also access the network. The bid-offer spread that dealers provide to clients is typically wider than what is observed in the interbank market. The bid-offer spread is sometimes measured in points, or pips, which are scaled to the last digit in the spot exchange rate quote. Exchange rates for most currency pairs (except those involving the Japanese yen) are quoted to four decimal places. For example, the bid-offer spread in the interbank market for USD/EUR might be 1.2500–1.2504. This is a difference of 0.0004, or 4 pips, while a dealer’s spread for the same currency pair may be 0.0006, or 6 pips. The bid-offer spread in the FX market, as quoted to dealers’ clients, can vary widely among different exchange rates and can change over time, even for a single exchange rate. The spread size is primarily influenced by the bid-offer spread in the interbank market, transaction size, and the relationship between the dealer and the client. A client’s creditworthiness can also be a factor, although, given the short settlement cycle in the spot FX market, credit risk is not the primary determinant of bid-offer spreads.Related Documents
- Directional Constants in Linear Functions: Analyzing Changes
- Marginal Propensity to Consume: Consumption and Income Relationship
- Economic Function Perspective: Elimination and Substitution
- Economies of Scale: Analyzing Minimum Production Inflation Points
- Production Cost Estimation: Optimizing Profits
- The Banking System: The Federal Funds Market
- The Distribution of Income: Losses in Efficiency Caused
- Measuring Sales Subsidies A Mathematical: Analysis of the Goods Market
- The Banking System: Multiple Expansion of The Money Stock
- The Banking System: Deposit Creation by a Single Bank
- The Banking System: Deposit Contraction The Process in Reverse
- The Banking System: Commercial Bank Balance Sheets
- Banking System: Loans & Checkable Deposits
- The Banking System: The Reserve Multiplier
- The Banking System: The Evolution of Banking
- Quadratic Curved Lines: Studying Parabolas that Open Upward and Downward
- Income Maximum Point Determinants: Discriminants in Economics
- Lagrange Multiplier Analysis in Economic Modeling
- Linear Functions with Negative Directional Coefficients
- Tax Function Analysis: Understanding the 'To' Constant
CFA L2 2024 Volume 1 - Quantitative Methods


































































































































Recommended Documents

Report
Tell us what’s wrong with it:
Thanks, got it!
We will moderate it soon!
Report
Tell us what’s wrong with it:
Free up your schedule!
Our EduBirdie Experts Are Here for You 24/7! Just fill out a form and let us know how we can assist you.
Take 5 seconds to unlock
Enter your email below and get instant access to your document