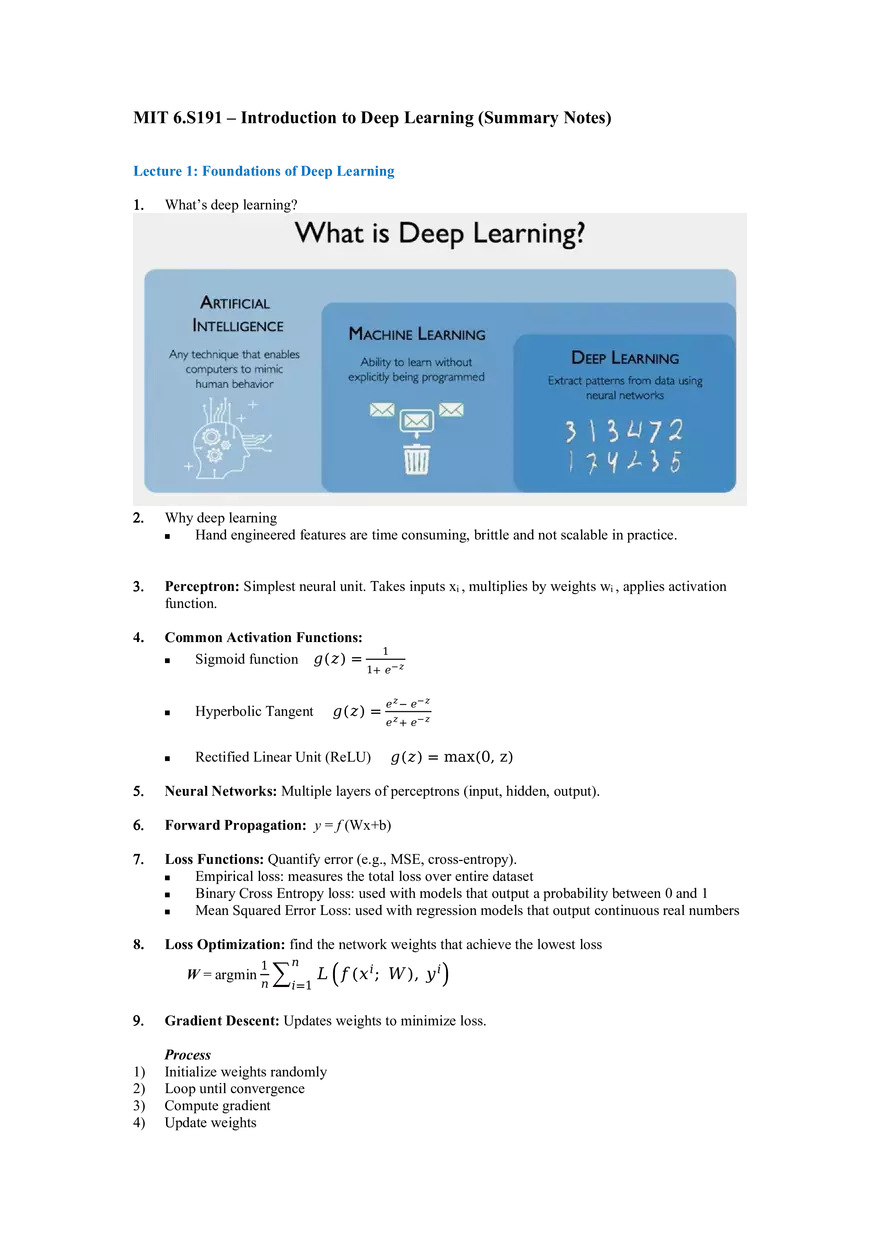
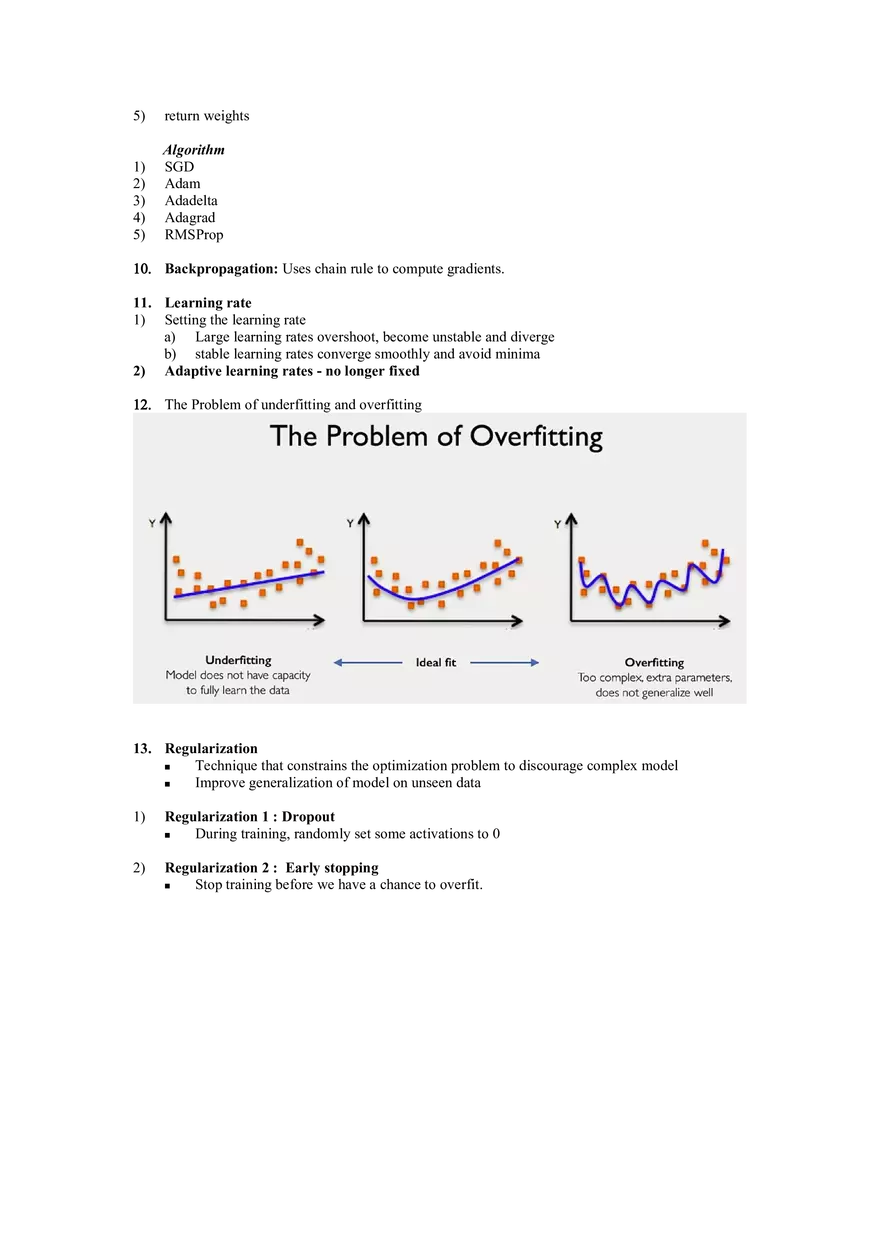
Introduction to Deep Learning - Lecture 1
Recommended Documents

Free up your schedule!
Our EduBirdie Experts Are Here for You 24/7! Just fill out a form and let us know how we can assist you.
Take 5 seconds to unlock
Enter your email below and get instant access to your document